An amateur incursion on how data science and machine learning can augment our understanding of cities. This issue is 937 words long & it should take 3.5 minutes to read through; hope you enjoy it!
A couple of decades ago I was obsessed with Folding@home, a distributed network effort that used the down-time of computers around the world to simulate and model the dynamics of proteins in search of novel medicines and therapeutics. Recently Deepmind’s AlphaFold has solved an important element of protein dynamics through Artificial Intelligence. Simply put the algorithm is able to predict the structure of proteins to a level of precision usually achieved through costly and time-consuming experimental techniques.
Artificial Intelligence and Machine Learning are slowly popping up in most fields of human interest. Until recently I felt like understanding and employing these technologies was well beyond the ability of non-technical folks. Last year however I spent a month dabbling with Coursera’s IBM Data Science Professional Certificate, a set of self-paced courses which cover the basics of machine learning, data analysis and visualization. I was immediately struck by the fact that you don’t have to understand everything in order to use these powerful algorithms.
Most scientists who had access to a computer in the 60s probably understood almost everything that was going on under the hood. This has not been the case for decades - today most of us employ computers in our daily life, learn to use complex software and at the same time have little to no understanding of what’s physically going on behind the monitor. The same level of abstraction is slowly becoming true for Machine Learning. I think the challenge for urban professionals - and most professionals dealing with complex issues - is to conceptually understand relevant algorithms and apply them to specific knowledge-domains. The advent of no-code will quickly remove the already-low barrier to entry in employing these tools in our daily workflows.
As an example, I recently came across a simple algorithm that can work wonders in clarifying relationships and clustering urban data in groups. K-Modes takes categorical data as its input and clusters them in groups with similar features. This is easier to understand on data that has two or three features (or dimensions). The following images show how the results of clustering algorithms look like in two and three dimensions.
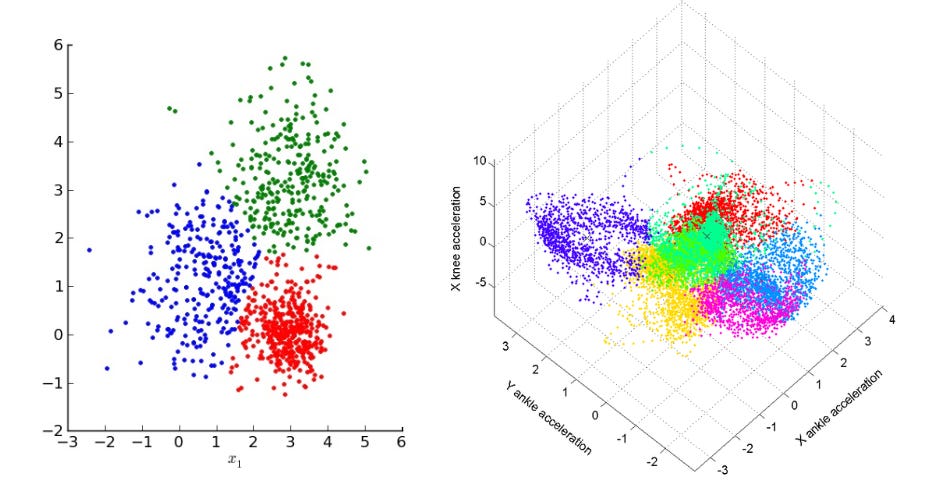
Low dimensions make it easy to visually understand that the algorithm has grouped similar variables together in clusters. The power of K-Modes however if that it can work for a larger number of dimensions. It is physically impossible for us to visualize more than three dimensions: similar to how we understand the rules driving the shape of a four-dimensional cube (a hypercube) even though we cannot “see” it. Mathematically the algorithm would go through an identical process to the one we can visualize but for more dimensions; it would then cluster data based on their similarity and dissimilarity. The output would be buckets of data that are related to one another across their features. It would then fall upon the professional to label and give meaning to clusters by looking at the correlated features of each group.
As an example imagine having a database of businesses in your city with a thirty or more of variables: number of employees, type of business, yearly turnover, neighborhood location etc. If you want to design an outreach campaign to clarify a new fiscal policy, it might be much more impactful if you could segment and group them in 10 or 15 clusters with similar kinds of businesses - not just their size, or location - but a more complex segmentation based upon all of the available variables. Think of the potential to better understand neighborhoods, social issues across the city, land value changes and so on. This extremely complex exercise is rendered by writing just two lines of code in Python. The complicated equations are already coded in a free module that you can import into your programming notebook. Most of the technical difficulties have already been removed.
kmodes = KModes(n_clusters=cost, verbose=2, max_iter=100) clusters = kmodes.fit_predict(mark_array)
When one thinks of algorithms and urban planning we typically imagine computers doing the crunching and spitting out the plan. That might be the case in the future, but for now they can serve as complex calculators; tools that can help us better understand the intricacies and subtleties of our cities.
Did you like this issue of thinkthinkthink? Consider sharing it with your network: Share
📚 One Book
The Lives of a Cell by Lewis Thomas
The Lives of a Cell is one of these uniquely ephemeral books where you can’t but feel sheer excitement at what’s coming for you in that next sentence. You often have to stop and think of the fact that a human mind has come up with such a brilliant, fun and complex combination of words to make you smile, mid-read. Some ideas are of course outdated - it is a 46 year old book after all - but the ability of Lewis’ writing to make science exciting, and biology just plain fun, is unrivalled.
📝 Three Links
Improve the News by Max Tegmark et al.\ Wielding “the algorithm” against the bubble.
Illuminated Equations by Matt Hall\ Employing design to simplify the understanding of complicated equations.
The complex grid by Mathieu Hélie\ On scaling the urban grid by breaking free of its arbitrary simplicity.
🐤 Five Tweets
CEO of the city
— balajis.com (@balajis) January 16, 2021
In a remote world, talent is mobile. Mayors no longer need to run for higher office — they can level up just by recruiting talent to their city. On the other hand, they can also \*lose\* talent if the city doesn’t perform.
More upside and downside than before.
I made some gifs of various types of fitness landscape for my speculation for the evolution of gene, society, design, and software. https://t.co/cFqb5cYfcL (CC-0) pic.twitter.com/V4sCSVKdad
— Baku 麦 (@_baku89) January 10, 2021
Don’t ever let anyone tell you that streets can’t be vibrant places to foster friendships & connect with neighbours. But as Donald Appleyard illustrated decades ago, the volume & speed of traffic, & the overall design of the streets, are social life dealbreakers. #StickyStreets pic.twitter.com/Spkgw9vzXF
— Brent Toderian (@BrentToderian) January 15, 2021
When ride sharing companies enter a new market vehicle ownership increases, traffic increases, transit use decreases. Not a good look, as they say. https://t.co/wodfWCNvWi
— Wrath Of Gnon (@wrathofgnon) January 14, 2021
The fastest trajectory is not always the shortest. pic.twitter.com/gxP7SfeCaW
— Maxim Leyzerovich (@round) January 12, 2021
This was the eighteenth issue of thinkthinkthink - a periodic newsletter by Joni Baboci on cities, science and complexity. If you really liked it why not subscribe?